背景
生产环境通常是运维工程师维护,如果出现异常也是优先运维工程师来排查,但是运维工程师不精通产品的业务逻辑,如果异常涉及到业务逻辑,就事倍功半了,遇到这种情况,运维工程师会找产品研发工程师协助,如果此时研发工程师不具备分析dump包的能力,解决问题的效率就会变的很低,所以掌握如何调试和排查生产环境异常,是研发工程师必须掌握的技能。windbg是在windows平台下,强大的用户态和内核态调试工具。相比较于Visual Studio,它是一个轻量级的调试工具,所谓轻量级指的是它的安装文件大小较小,但是其调试功能,却比VS更为强大。它的另外一个用途是可以用来分析dump数据。
微软windbg下载
故障发生
8月21日下午4点48分左右客户的4台Web服务器同时CPU99%预警
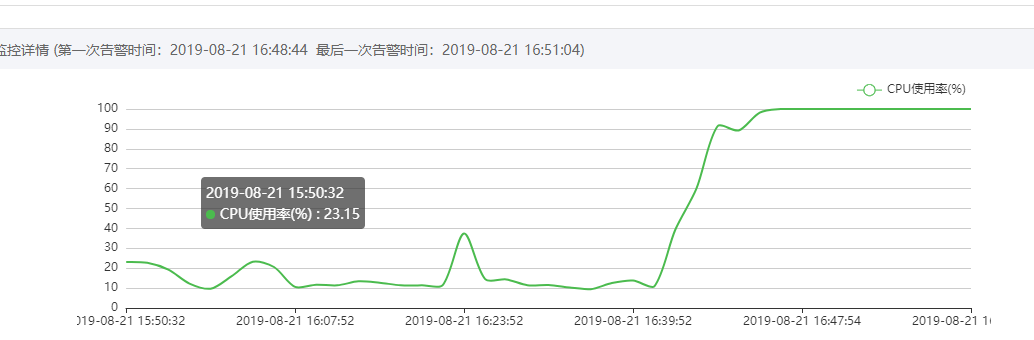
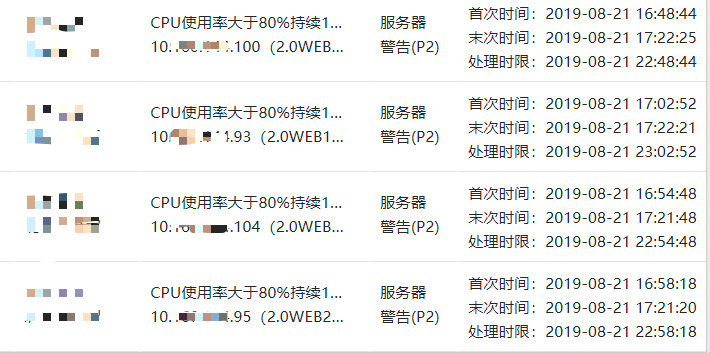
服务器抓包
任务列表生成进程的转储文件
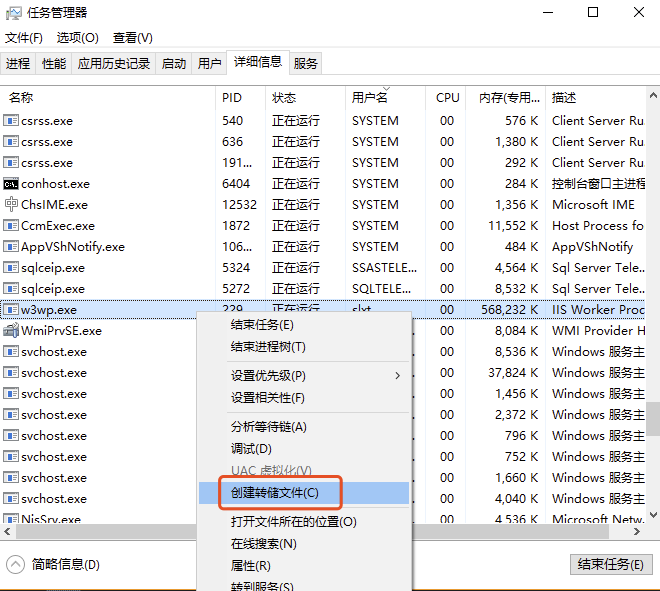
dump包解压和传输同时也没闲着
因为昨晚有程序更新,最先怀疑程序包问题,所以进行人工源码分析,没发现明显问题
windbg dump分析
本文涉及到的命令
1 | .load //加载模块 |
打开dump包,这里直接打开windbg后拖转到程序界面即可
.load 命令 加载SOS.dll,SOS.dll 扩展提供了大量用于检查托管堆的有用命令
1 | Loading Dump File [D:\w3wp.DMP] |
!tp 命令 分析线程池,可以看到CPU利用率已经100%了
1 | 0:000> !tp |
!runaway 命令 显示当前进程的所有线程用户态时间信息,可以看到线程时间最长的是42线程
1 | 0:000> !runaway |
42线程时间最长,所以先查看42主线程调用堆栈
1 | 0:000> ~42 s |
根据上面的堆栈信息,此时已经定位到具体出问题的接口是
UpdateRoomDjOverDusDays
通常100%CPU会怀疑死循环和无限递归,搜索代码分析,发现有很多个循环,但都很难引起死循环或者无限递归。
此时陷入尴尬,继续思考…
看到上面的线程CPU时间超过1分钟的有多个,逐个打开看堆栈
~47 s
~50 s
~49 s
发现堆栈信息都是相同的,是同一个接口调用
会不会是多线程一起跑,导致吃掉了所有CPU…
为了印证这个猜想,继续分析源码,看看是否有开启多线程的地方…果然找到了,如下图

破案
短时间内运行多次调度任务,如何做到的?
分析代码发现,这个接口的用途是调度任务,这个调度任务出厂时是每天凌晨1点执行一次,正常情况不会出现多次调用,分析有以下2种情况会出现多次调用
- 手动触发,调试接口,这个无日志,无证据,只能人工排除
- 人工将调度任务的执行间隔调整到其他间隔,比如一分钟一次,就可以造成多线程堆积
因为第一种情况无法确定,找不到证据,所以用排除法,先去找第二种可能的证据
首先去找系统的操作日志,发现的确在这个时间段有人操作个调度任务模块的功能,由于日志粒度不够细,无法断定是操作了什么功能
接下来就去找对应调度任务的运行日志,发现了问题…如图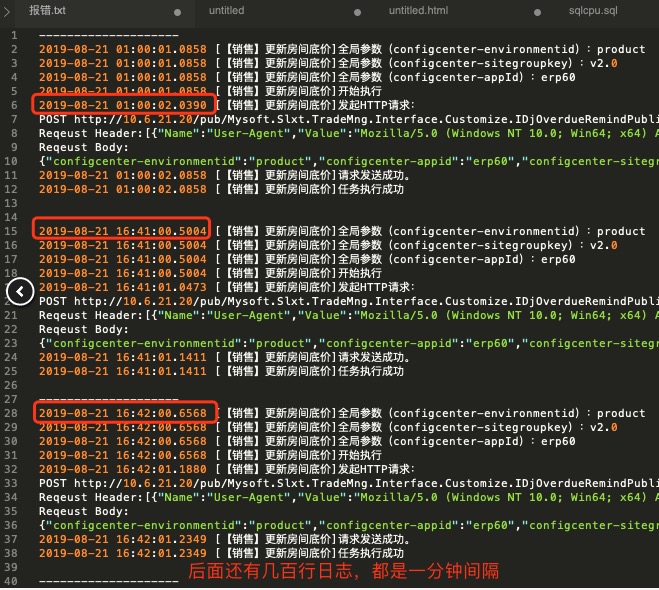
上图中,第一个时间是凌晨1点的正常调度
但是在 16:41 分又调度了一次
接着 16:42 分又开始了一次
…后面还有30多次调度,每一个都是间隔一分钟
结论
到这里所有的问题已经得到证实
这个调度任务在16:41分时被人为将调度间隔改成了1分钟调度一次,由于是异步执行,每次调度都会立即返回,修改后30分钟左右才改回来。 在半小时内被调度了30多次,导致线程堆积,出现了瞬时CPU99%,20分钟后又逐渐下降(因为任务逐渐都执行完了) 后与相关操作人员证实,确实有进行过调度间隔改动,目的是为了手动触发调度任务。但由于不知道内部机制,配置改动后没有及时还原。 而且上面16:41分的最初调度时间也和最初的CPU预警时间吻合。

